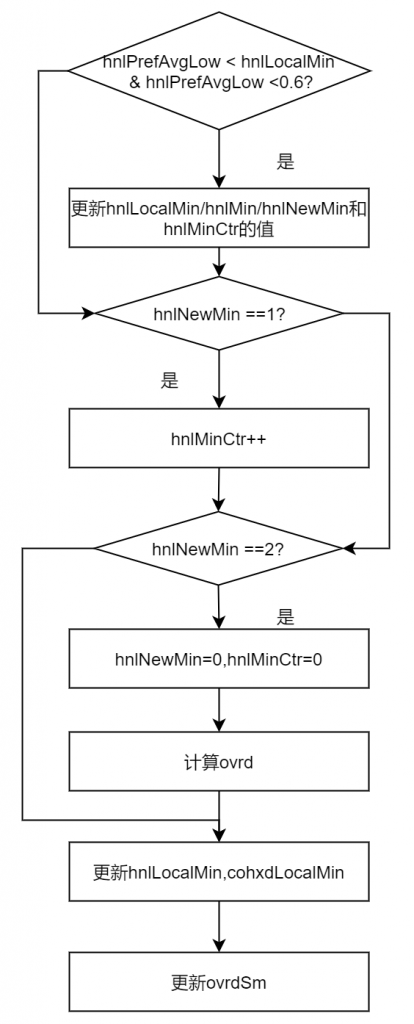
取消大小周了,周末有了更多的时间来自己学习。给自己立个flag,两周内把fullaec.m里面的线性滤波器、NLP等部分弄懂,发博客;再2~3周的时间看webrtc的AEC3的代码,同样发博客整理;然后再2~3周的时间看一下speex里面的AEC算法。 本次继续更新非线性处理部分。在学习过程中,参考了《实时语音处理实践指南》相关内容和网上有关博客的内容,在此对相关作者表示感谢。 非线性处理部分 计算完hnled,接下来开始计算ovrd。 hnlLocalMin是对hnlPrefAvgLow的最小值跟踪,其初始值为1…
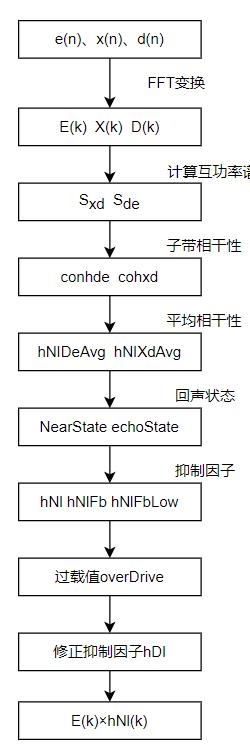
取消大小周了,周末有了更多的时间来自己学习。给自己立个flag,两周内把fullaec.m里面的线性滤波器、NLP等部分弄懂,发博客;再2~3周的时间看webrtc的AEC3的代码,同样发博客整理;然后再2~3周的时间看一下speex里面的AEC算法。 本次更新非线性处理部分。在学习过程中,参考了《实时语音处理实践指南》相关内容和网上有关博客的内容,在此对相关作者表示感谢。 非线性处理 非线性处理的主要思想: WebRTC是利用信号之间的频域相干性c(0<=c<=1)来衡量误差信号中残留回声的大小的。首…
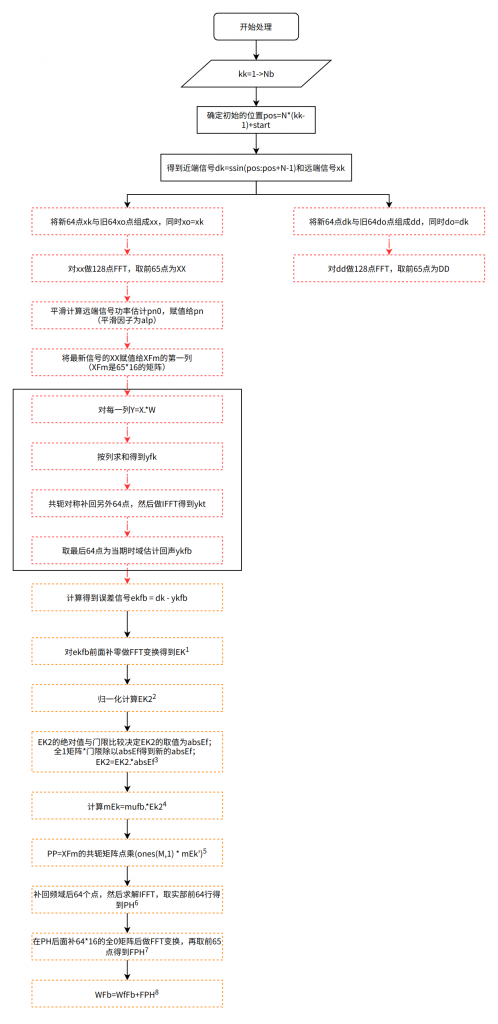
取消大小周了,周末有了更多的时间来自己学习。给自己立个flag,两周内把fullaec.m里面的线性滤波器、NLP等部分弄懂,发博客;再2~3周的时间看webrtc的AEC3的代码,同样发博客整理;然后再2~3周的时间看一下speex里面的AEC算法。然后再2~3周吃一吃公司的算法,但是这个整理只是自己学习用,不会做任何公开发布。 所以下面开始第一个flag的内容。这周只有空看完了线性部分,仿佛没有看到这里面有DTD的部分,所以先发一下线性部分,后面整理一下非线性部分。在学习过程中,参考了《实时语音处理实践指南》相…

第一节 回声消除原理 声学回声消除主要用来解决双端通信中回声干扰的问题。如下图所示,A、B两段正在进行远程语音通话,B端语音被麦克风采集后转换成电信号,经过网络传输到达A端,由A端扬声器播放出来,如果在A端没有做AEC处理,那么这个声音就会被A端的麦克风采集传回到B段,从而干扰正常的语音通信。 AEC目前已经形成了以自适应滤波处理联合回声后处理为主的技术方案。其中,自适应滤波器用来模拟和追踪真实的“回声路径”,并由收敛出的“回声路径”(实际为滤波器系数)估算出回声信号,再从近端纯净语音和回声的混合信号中减去估计的回…

第三章 语音端点检测(VAD) WebRTC中集成了基于RNN模型的VAD检测算法,该方法也作为WebRTC新一代AGC算法的一个子模块而存在。 第一节 特征选取 一个好的VAD特征应该具备以下特性: 区分能力:含噪语音和仅含噪声音频的分离度应该尽可能的大。理论上的最好效果是让语音特征和噪声特征没有交集(实际很难,因为会有相似) 噪声鲁棒性:背景噪声会造成语音失真,这会影响提取的特征区分能力。 基于能量的特征:基于能量的方法可以将宽带语音分成各个子带,求各个子带的能量。这是因为语音在2kHz以下频带含有大量的能量,…

本部分知识基于葛世超等人著《实时语音处理实践指南》一书进行整理。第一章 信号处理 第一节 语音基础知识 语音信号是实信号。 语音信号是时变的,每秒约产生10个音节,所以在10~30ms内可以看成是准静态的。 为什么要加窗处理? 答:对连续的语音分帧做STFT处理,等价于截取一段时间信号,对其进行周期延拓,从而变成无限长序列,然后对该无限长序列做FFT变换,但是这一截断并不符合傅里叶变换的定义,因此会导致频谱泄露和混叠。泄露会导致幅度较小的频点淹没在幅度较大的频点泄漏分量重,而混叠会在分段拼接处引入虚假的峰值,进而不…
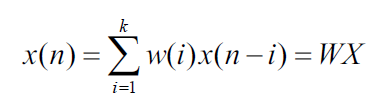
在实现维纳滤波器和预测器的时候,需要计算数据的自相关矩阵的逆。但是当数据量比较大的时候,计算矩阵的逆花费的代价比较大,所以需要使用Levinson-Durbin算法来实现系数的求解。 一、数据模型 k阶前项维纳预测器: 对上述模型进行一下调整,可以得到 所以a(0)=1, 。 注意:在Levinson-Durbin算法中,求解的是a(i),不是w(i)。 二、Levinson-Durbin迭代算法的实现步骤 以下是迭代算法的步骤,其中m是预测器的阶数。 初始值: 其中r(i)是数据的自相关矩阵。

最近评论
davidcheung 发布于 1 年前(02月09日)
tk88 发布于 1 年前(02月07日)
cuicui 发布于 2 年前(10月20日)
niming 发布于 2 年前(09月19日)
davidcheung 发布于 3 年前(08月16日)
Nolan 发布于 3 年前(07月25日)
davidcheung 发布于 4 年前(06月19日)
aobai 发布于 4 年前(03月13日)
匿名 发布于 5 年前(12月30日)
小奥 发布于 6 年前(12月12日)