取消大小周了,周末有了更多的时间来自己学习。给自己立个flag,两周内把fullaec.m里面的线性滤波器、NLP等部分弄懂,发博客;再2~3周的时间看webrtc的AEC3的代码,同样发博客整理;然后再2~3周的时间看一下speex里面的AEC算法。
本次更新非线性处理部分。在学习过程中,参考了《实时语音处理实践指南》相关内容和网上有关博客的内容,在此对相关作者表示感谢。
非线性处理
非线性处理的主要思想:
WebRTC是利用信号之间的频域相干性c(0<=c<=1)来衡量误差信号中残留回声的大小的。首先计算麦克风输入的近端信号d(n)与误差信号e(n)的频域相干性cde【实际上e(n)就是理想情况下我们去除回声后的纯近端语音信号,但是实际上还会有一些残留回声,因此可以简单地把cde当作残留回声在误差信号中的占有比例。假设线性阶段正常运行,cde越接近于1,说明近端信号和误差信号相似性越高,越不需要对误差信号做控制;相反,cde越小,越需要对误差信号做抑制。】。另外还会计算近端信号d(n)和远端信号x(n)之间的频域相关性cxd,令c'xd=1-cxd,c'xd越大,说明回声残留越小,越不需要一直;c'xd越小,说明回声残留越大,越需要抑制。由cxd和c'xd做进一步的处理操作,计算出每个频带相应的抑制因子sγ(k)。将抑制因子与误差信号对应的频带相乘,从而实现残留回声的抑制。
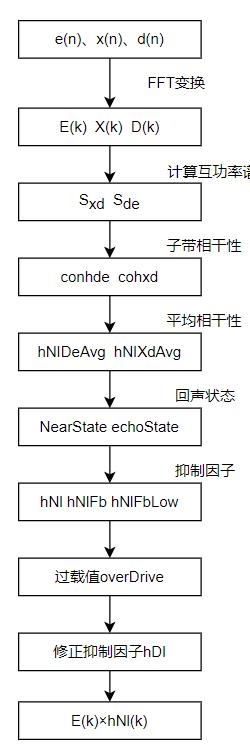
下面回到matlab代码里面。由于非线性处理部分较长,所以一部分一部分来讲述。
第一部分是FFT变换到平均相干性的计算。
首先将ekfb与上次的误差组合成新的ee,即ee=[eo;ekfb],然后对ee、xx、dd都要进行先加窗再做FFT变换得到ef、xf、df。这里加窗目的显而易见,就是为了减少频谱泄露,提高频谱的分辨率。
然后将xf存放在xfwm的第一列,df存放在dfm第一列。然后把dldx(即“一个分析部分”里面计算出来的权重矩阵能量最大的那块的索引值)指向的那一列赋值给xf,这样从xfwm矩阵里把真正要处理的近端信号对应的远端参考信号获取到。
xfwm(:,1) = xf;xf = xfwm(:,dIdx);dfm(:,1) = df;
然后计算功率谱,它们都是65*1的矩阵。
Se = gamma*Se + (1-gamma)*real(ef.*conj(ef));Sd = gamma*Sd + (1-gamma)*real(df.*conj(df));Sx = gamma*Sx + (1 - gamma)*real(xf.*conj(xf));
然后计算误差信号和近端输入信号(包括感兴趣信号和回声)的互功率谱Sed、远端参考信号和近端输入信号的互功率谱Sxd。
Sxd = gamma*Sxd + (1 - gamma)*xf.*conj(df);Sed = gamma*Sed + (1-gamma)*ef.*conj(df);
然后计算误差信号和近端信号的相关性cohed,远端信号和近端信号相关性cohxd。cohxd越小,表示回声越小,cohxd越大,表示回声越大。
然后计算cohed在echoBandRange范围内的平均相干性。之所以是在这个范围内的,是考虑到回声主要集中在较低的频带,且人耳实际到高频带感知有限,所以对于高频带我们不拿来计算,节省计算量。将计算结果保存在cohedAvg,表征这是第kk个块的情况。cohedAvg是一个(Nb+1)*1的向量。
cohed = real(Sed.*conj(Sed))./(Se.*Sd + 1e-10);cohedAvg(kk) = mean(cohed(echoBandRange));cohxd = real(Sxd.*conj(Sxd))./(Sx.*Sd + 1e-10);
在《实时语音处理实践指南》的解析中,没有对cohxd做进一步处理,但是在我所参考的代码里面对其进行了进一步处理,即
H(z)=0.56/(1+0.44z-1)
然后依旧是求解了在感兴趣频带的cohxd的平均值,保存在了cohxdAvg。cohxdAvg和cohedAvg貌似后面没使用?

然后继续往下。
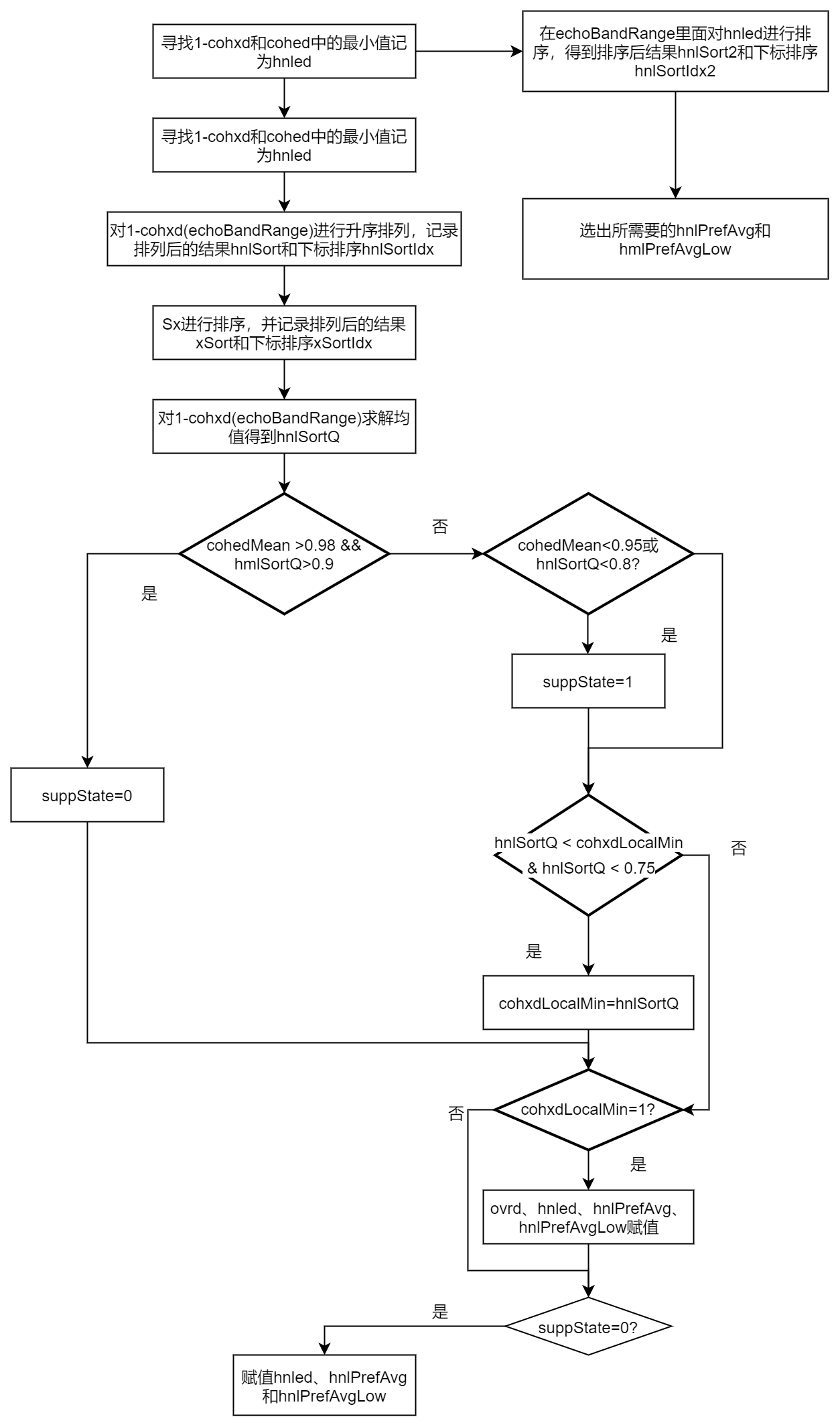
首先寻找1-cohxd和cohed中对应每个元素的最小值,存入hnled。1-cohxd的值越大,说明回声越小,否则回声越大。cohed的值越大,说明回声越小,否则回声越大。【此处应该是假设d里面包括感兴趣的信号s】。该值越大,说明回声在对应频率分量上越小,该频率分量越不需要一直回升。之所以取两者判断,也是为了最大可能消除回声。
hnled = min(1 - cohxd, cohed);
然后对1-cohxd(echoBnadRange)和Sx进行升序排列。然后计算1-cohxd(echoBandRange)的均值。这里计算出来的结果hnlSortQ其实表示了远端和近端不相关性的平均值(因为cohxd表示的是相关性,所以1-cohxd是不相关性)。值越大,相关性越差,实际上回声越小。然后在感兴趣频带对hnled进行升序排序。
[hnlSort,hnlSortIdx] = sort(1-cohxd(echoBandRange));[xSort, xSortIdx] = sort(Sx);hnlSortQ = mean(1 - cohxd(echoBandRange));[hnlSort2, hnlSortIdx2] = sort(hnled(echoBandRange));
我们从hnled中取两个值,一个值是取在排序后的后四分之三的地方的一个值,记为hnlPrefAvg;另一个是排序后二分之一的地方的值,即为hnlPrefAvgLow。
hnlQuant = 0.75;hnlQuantLow = 0.5;qldx = floor(hnlQuant*length(hnlSort2));qldxLow = floor(hnlQuantLow*length(hnlSort2));hnlPrefAvg = hnlSort(2);hnlPrefAvgLow = hnlSort2(qldxLow);
接下来我们就要判断是否要进行残余回声的抑制了,这里依据了两个条件:其一是cohedMean,即误差信号与近端信号的相关性,它们越相关(即值越大),说明越不需要抑制回声;其二是hnlSortQ,即近端信号和远端参考信号的非相关性,它们越不相关(即值越大),说明越不需要抑制回声。这里cohedMean的门限值为0.98,hnlSortQ为0.9,说明WebRTC的开发人员宁可牺牲一部分双讲效果,也不愿意接受回声残留。所以可以说这个算法是抑制回声较好,但是双讲可能效果较差。若都大于门限值,则不需要抑制回声,suppState=0;否则若cohedMean<0.95或hnlSortQ<0.8,则需要进行抑制,suppState=1,若为其他情况,则按照上一帧的选择来进行。
if cohedMean > 0.98 && hnlSortQ >0.9suppState = 0;elseif cohedMean <0.95 | hnlSortQ < 0.8suppState = 1;end
cohxdLocalMin的初始值为1,代表远端和近端完全不相关,这里会判断计算得到的远端和近端不相关性hnlSortQ是否小于前一次不相关,如果hnlSortQ小于前一次且小于0.75,则更新一次cohxdLocalMin:
if hnlSortQ < cohxdLocalMin & hnlSortQ <0.75cohxdLocalMin =hnlSortQ;end
如果cohxdLocalMin=1,要么说明远端和近端完全不相关,要么就是cohxdLocalMin没有更新,既然非相关性非常大,则说明有回声的概率很小,那么使用较小的ocrd(over-drivend)值和较大的hnled(65*1)值,这样做是为了当回升路径接近于0时,避免发生抑制,例如耳机通话场景。
if cohxdLocalMin == 1ovrd = 3;hnled = 1-cohxd;hnlPrefAvg = hnlSortQ;hnlPrefAvgLow = hnlSortQ;end
另外,如果suppState==0,则认为不需要进行回声抑制,cohedMean和hnlSortQ都接近于1,这种情况下,hnled的值也接近于1。
if suppState == 0:hnled = cohed;hnlPrefAvg = cohedMean;hnlPrefAvgLow =cohedMean;end
博客内容排版有些混乱,如需访问原版,请点击这里访问,访问密码请关注个人公众号【小奥的学习笔记】,回复fullaec获取。



文章评论