计算参考信号和采集信号的时延:GetDelay()
AEC3中的时延估计算法是使用计算滤波器能量最大块来作为延迟估计值,它是当滤波器收敛到一定程度时,计算所有滤波器系数的能量,取峰值的系数(tap)对应的delay就是对齐需要的delay。它是由步长为0.7的5个时域的NLMS滤波器组成,每个滤波器默认为32个块,每个块有16个样点,总计有32*16=512个样点,5个滤波器理论上共有512*5=2560个点,但实际上5个滤波器在时域上互相重叠8块(即输入的信号在时间上存在重叠),所以实际上5个滤波器可以估计2560-8*16*4(重叠一共有4块区域)=2048个样点。由于输入信号是经过分频后(低频0~16kHz)再经过4倍下采样的信号(实际采样率为4000Hz),所以实际最多能估计的延迟为2048/4000=512ms。
用匹配滤波器计算的延时有更好的可靠性,计算量也有所增大。
该部分主要包括两个部分,计算时延的EchoPathDelayEstimator类下的EstimateDelay()函数和ComputeBufferDelay()。首先分析第一个函数。
该函数的输入参数如下:
|
参数名
|
类型
|
说明
|
|
render_buffer
|
const DownsampledRenderBuffer&
|
进行了降采样(采样率4000Hz)的参考信号
|
|
capture
|
const std::vector<std::vector<float>>&
|
输入的采集信号
|
整体的流程图如下:
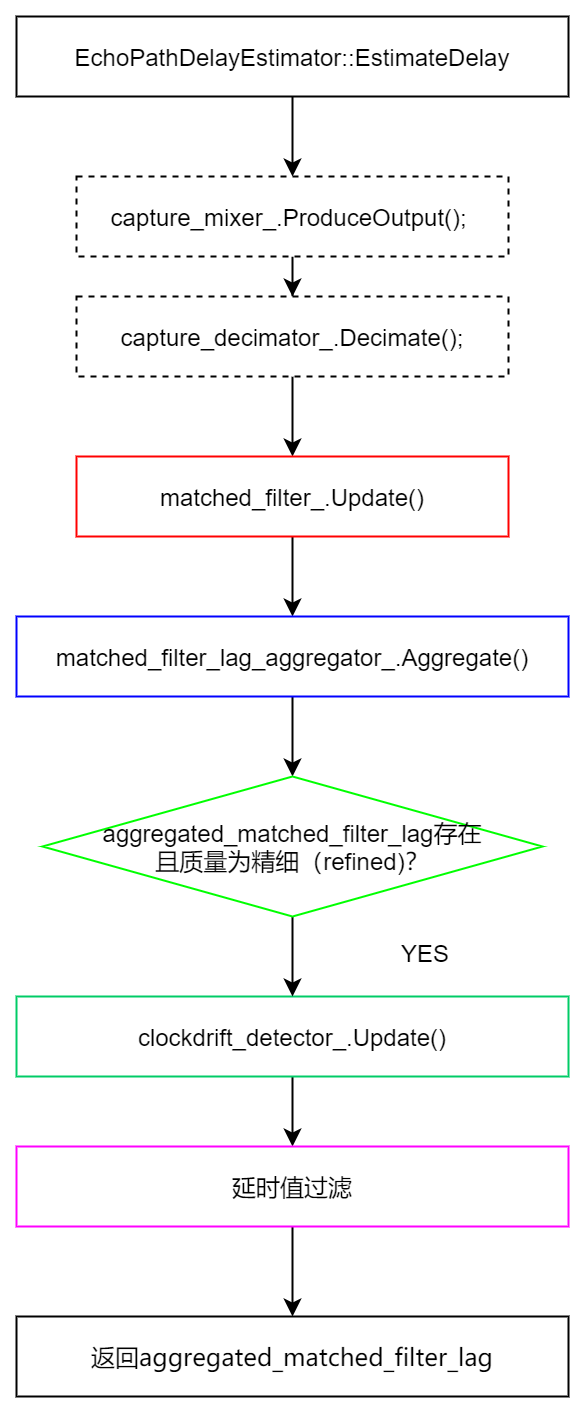
Step1:预处理
对应上图中的虚线框部分,主要是对近端信号做downmix和resample。在这里不重复。
Step2:匹配滤波器更新
匹配滤波器实际上里面就是5个NLMS滤波器,具体数据的组织方式在前面已经也说了,具体不再重复。NLMS滤波器更新的核心是MatchedFilterCore()这个函数,它的主体就是NLMS的更新公式,它本质上就是让误差最小(即采集信号和经过滤波之后的参考信号的误差)。因为是纯NLMS的理论,这里就不再重复了。但是需要注意的是,它只在以下两个条件下进行更新:
- 近端语音帧没有超过32000或-32000。
- 远端能量大于一定阈值。
也就是说,若近端语音出现爆音,则对齐不进行更新,也就是说一些爆音场景下可能回声消除效果一般;另外,远端能量如果小于阈值,则对齐也不进行更新,这才实际场景中例如耳机残留回声可能也会带来效果的影响。
Step3:计算每个滤波器延时值
将匹配滤波器中的滞后估计为到滤波器中对匹配滤波器输出贡献最大的部分的距离。 这被检测为匹配滤波器的峰值。
延时值可信度包括三个部分:
- 延时值落在滤波器>2且<10范围内
- 误差能量小于近端能量的0.2倍
- 滤波器是否更新
Step4:从5个滤波器中挑出最佳延时值估计
MatchedFilterLagAggregator::Aggregate()函数。它是首先选取5个滤波器最佳的一个结果来更新best_accuracy和best_lag_estimate_index【挑选原则:滤波器更新且可信度为真,且accuracy最大,其中accuracy为近端能量-误差能量】。如果进行了更新,那么就用直方图选择最佳的估计值。它实际上使用一个历史窗口来统计过去的延时值,然后统计出现最多的延时值是哪个,如果这个值出现次数大于了20次,则认为质量较高,否则认为质量较低。
Step5:时钟漂移检测
对于质量较高的延时值会用来做时钟漂移检测。由于后面没有使用。这里不再累述。
Step6:对齐远端数据
时延会进行一次重采样,恢复为原来采样率下的延时情况。
质量好和差的延时值都会被拿来进行远端对齐。再者,如果两次延时值的质量都为高,则如果延迟增量小于某一阈值,就会认为延时没有改变。
Step7:处理回声路径变化
它包括延迟改变,增益改变,时钟漂移
主辅滤波器处理声路径变化,并将非线性增益设置为初始状态
【Step5~Step7参考文档:https://blog.csdn.net/myangel13141/article/details/107175522/】
EchoRemoverImpl::ProcessCapture
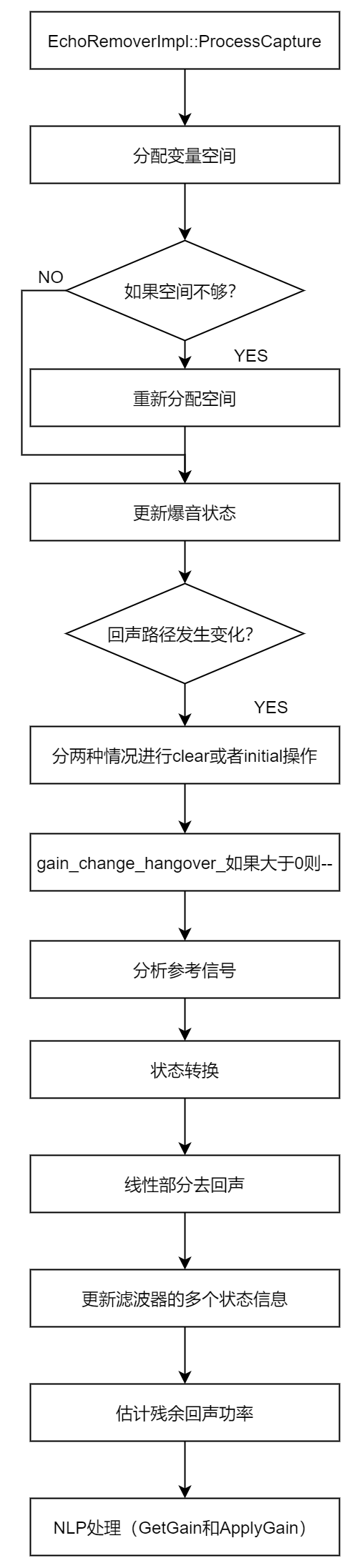
首先分配变量空间(见下面整理的表格)。如果声道数为大于2,则分配空间不够,按照实际声道数分配空间。再根据传入的爆音状态变量capture_signal_saturation更新AEC里面的爆音状态。
第二,判断回声路径是否发生变化,若发生变化则进行进一步操作,否则走第三步。回声路径变化依据echo_path_variability中的两点,两者中有一个符合即为发生变化:一为gain_change改变,即回声大小发生改变;二为delay_change不为kNone。如果是gain_change为true的这种情况,是需要每三帧(gain_change_hangover_)做一个判断,若已经满三帧了,则gain_change为true不会改变,并且将gain_change_hangover_重置为3;若没有满3帧,则gain_change置为false。完成上述操作后,对subtractor_的主、副滤波器进行clear,对aec_state_也进行clear。如果是delay_change不为kNone这种情况,则将initial_state_设置为true。然后若gain_change_hangover_大于0,则对其进行自减。
第三,分析参考信号。分析参考信号分为两步:第一步是识别具有窄特征的本地频段,第二步是标识信号是否具有单个强窄带分量:
- 远端信号中某个频率点的幅度大于左右频点幅度的3倍,则认为是弱窄带频率分量;
- 远端信号中某个频率点的幅度大于左右频点的100倍,则认为该频率点是强窄带分量。
第四,状态转换。若当前Initial_state_为false且前一帧的initial_state_为true,则认为需要进行状态转换了,线性滤波器substractor_的main_gains_、shadow_gains_、main_filters_、shadow_filter_都退出初始化,suppression_gain_也设置initialstate为false。
以上是基础部分,接下来开始处理部分。
线性处理部分
AEC3的线性滤波器部分使用了主辅滤波器结构(即main_filters_和shadow_filter_),一个是卡尔曼滤波器,另一个是NLMS滤波器,卡尔曼滤波器更新比较慢,而NLMS更新比较快,这种方法取代了双讲检测。整体来说思路,主滤波器会通过计算失调和步长的变化来保证主滤波器不会发散,但是缺点是可能误差较大;辅助滤波器会一直更新,跟踪回声的路径,当辅助滤波器发散的时候,会将主滤波器系数拷贝到辅助滤波器。
这两个滤波器在双讲时卡尔曼滤波器很稳健,不易发散,而NLMS会发散;但是回声路径发生变化时NLMS可以较快收敛,两者结合取最小输出。
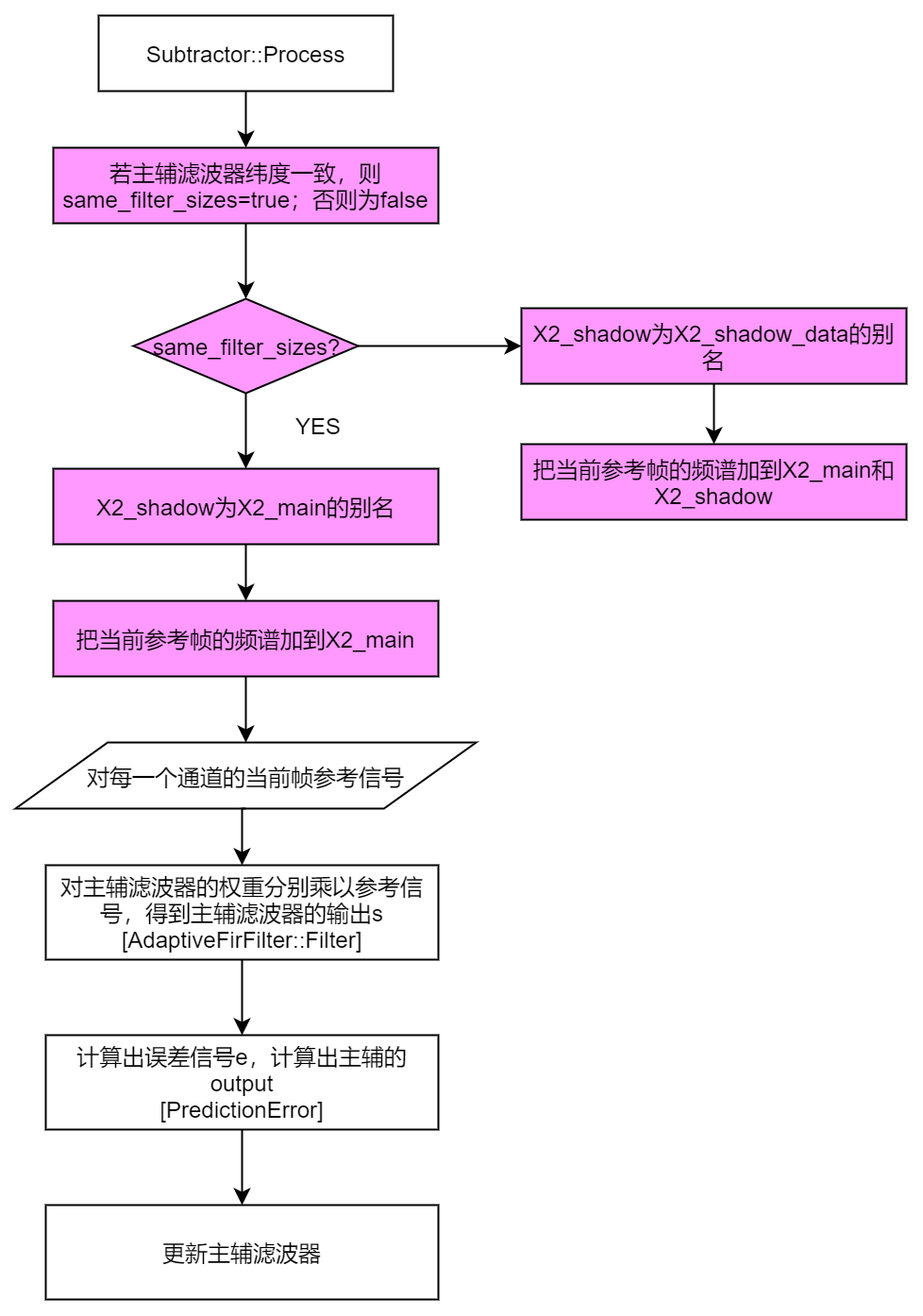
主要都在subtractor_.Process过程中。
第一步,紫色的部分是对参考信号进行处理。若主辅滤波器长度一致,则令same_filter_sizes为true,否则为false。若same_filter_sizes为true,代表两个滤波器长度一致,实际上代表他们是一样的,那么令X2_shadow为X2_main的别名(后面X2_shadow是辅助滤波器使用的,因为两个滤波器长度一致,所以他们实际上是完全一样的,由于后面会分别对主辅滤波器操作,所以这里使用这样一个别名,代表若长度一致的话,后面的操作是对同一个滤波器操作),然后把当前参考帧的频谱加到X2_main;若两者长度不一致,则X2_shadow是X2_shadow_data的别名,然后把当前参考帧的频谱分别加到X2_main和X2_shadow。
第二步,滤波。
main_filters_[ch]->Filter(render_buffer, &S);PredictionError(fft_, S, y, &e_main, &output.s_main);shadow_filter_[ch]->Filter(render_buffer, &S);PredictionError(fft_, S, y, &e_shadow, &output.s_shadow);
Filter是滤波,实际上就是S=W^HX。其中X代表参考信号频谱,W代表主滤波器或者辅助滤波器的滤波器系数,S代表滤波后的结果频谱。PredictionError实际上就是下面的公式:e(t)=y(t)-s(t)和o(t)=kscale*e(t)。其中e为e_main或e_shadow。o为output.s_main或output.s_shadow。kscale=1.0f / kFftLengthBy2。
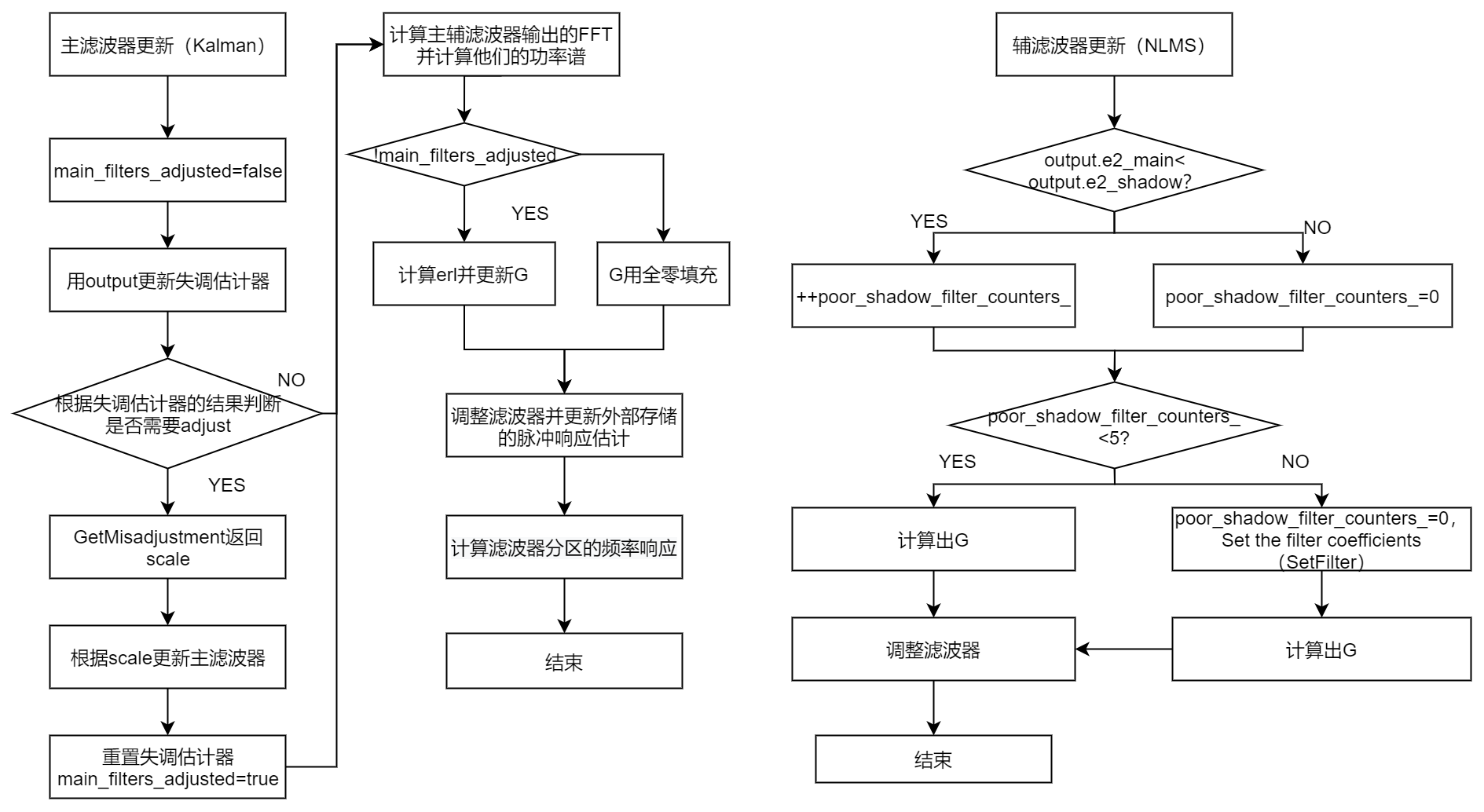
第三步,更新主辅滤波器。对于主滤波器来说,其主要计算的公式如下:
mu = H_error / (0.5* H_error* X2 + n * E2)
H_error = H_error - 0.5 * mu * X2 * H_error
G = mu * E H_error = H_error + factor * erl
H_error = H_error + factor * erl
H(t+1)=H(t)+G(t)*conj(X(t))
对于辅滤波器来说,其主要计算的公式如下:
如果X2[k]>current_config_.noise_gate,那么mu[k] = current_config_.rate / X2[k];否则mu[k]=0。
G = mu * E * X2
H(t+1)=H(t)+G(t)*conj(X(t))
其中k是第k个频点。
第四步,计算频谱。首先,选择主滤波器或辅助滤波器输出中最适合传递给抑制器的那一个,并且在切换的时候进行平滑过渡。然后计算采集信号的加窗FFT为Y,线性输出结果的加窗FFT为E,计算残余回声的功率谱S2_linear((Y-E)^2)。计算Y的频谱Y2,E的频谱E2。下面重点讲一下第一部分,也就是FormLinearFilterOutput。
bool use_main_output = true;//use_shadow_filter_output_由config_.filter.enable_shadow_filter_output_usage确定if (use_shadow_filter_output_) {//即便config设置用辅助滤波器也必须满足以下两个条件才可以用辅助滤波器,否则只能用主滤波器:// 1. 由于主自适应滤波器的输出一般要优于辅助滤波器的输出,因此在选择阴影滤波器输出时要增加一个裕度和阈值,符合这里的条件才可以选择辅助滤波器。if (subtractor_output.e2_shadow < 0.9f * subtractor_output.e2_main &&subtractor_output.y2 > 30.f * 30.f * kBlockSize &&(subtractor_output.s2_main > 60.f * 60.f * kBlockSize ||subtractor_output.s2_shadow > 60.f * 60.f * kBlockSize)) {use_main_output = false;} else {// 2.主滤波器发散了(即辅助滤波器的结果功率谱大于主的,且主的比采集的还低)if (subtractor_output.e2_shadow < subtractor_output.e2_main &&subtractor_output.y2 < subtractor_output.e2_main) {use_main_output = false;}}}//使用哪个作为输出还需要依赖于main_filter_output_last_selected_的选择(默认为true第一步肯定为true,后面依赖于use_main_output的值)// 如果from和to一致,则把to赋值给out,应该to的长度大于等于from// 如果两者不相等,则对于前30个点,使用from和to平滑赋值给out,即//平滑系数a=1/(30+1),out[k]=a*to[k]+(1-a)*from[k]//对于超过30个点的其余点,则将to直接赋值给outSignalTransition(main_filter_output_last_selected_ ? subtractor_output.e_main: subtractor_output.e_shadow,use_main_output ? subtractor_output.e_main : subtractor_output.e_shadow,output);main_filter_output_last_selected_ = use_main_output;
至此,线性处理部分结束。
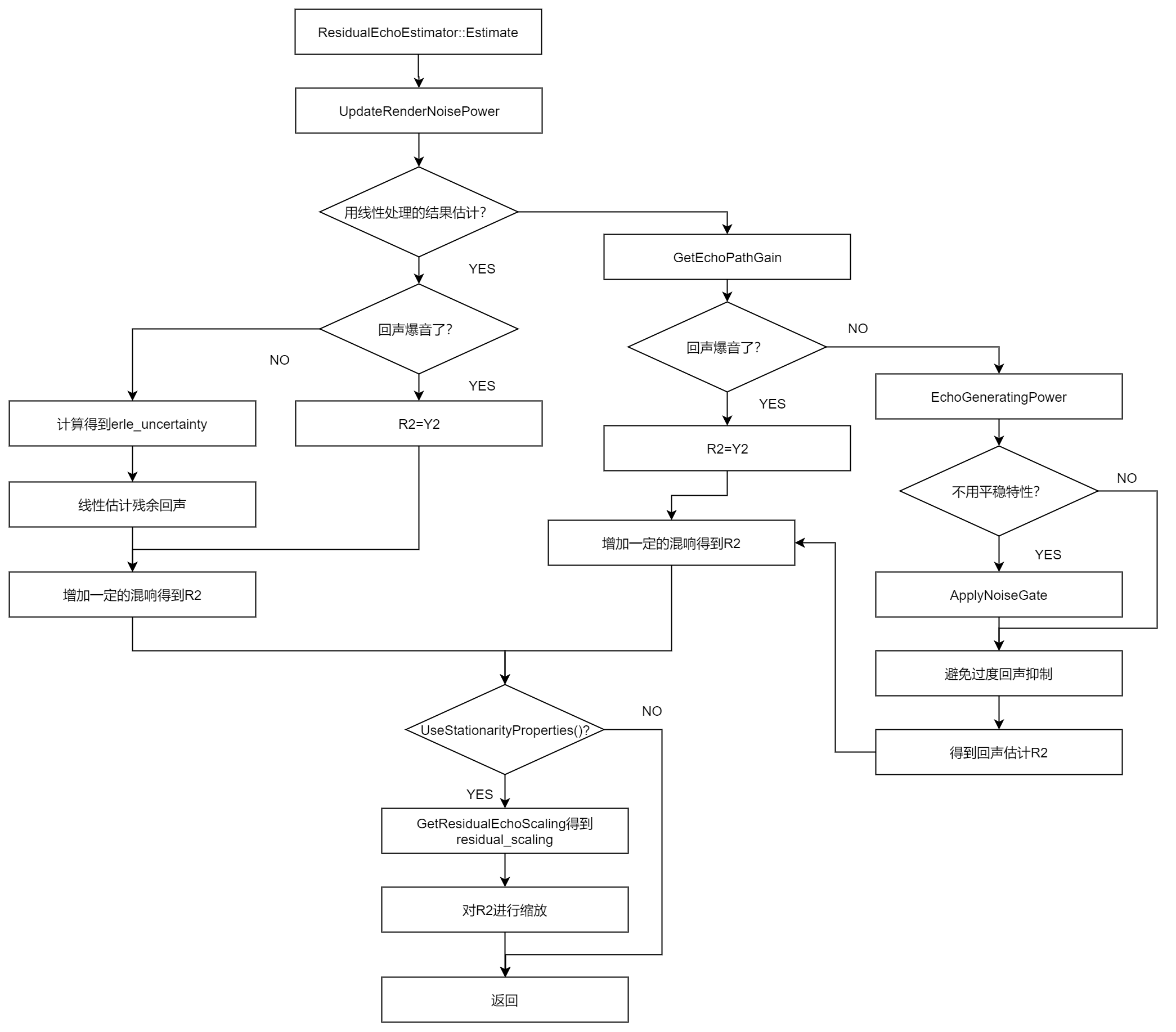
第一步就是更新参考信号的噪声功率,它分为以下两步:
1.得到参考信号的功率谱render_power;
2.以最小统计方式估计稳态噪声功率。
第二步就是生成残余回声估计。它依赖于一个变量分为了两部分,就是是否使用线性处理的结果来做残余回声估计,决定这一点依赖于两个条件,分别是filter_quality_state_.LinearFilterUsable() 和config_.filter.use_linear_filter,两者缺一不可。
1.若使用线性处理的结果来做残余回声估计,则先判断参考信号是否爆音,若爆音了,则认为残余回声估计就是参考信号,这样做是因为我们认为回声足够大到淹没了我们感兴趣的说话声,所以直接全部去掉就可以了,这样的缺点是在有少许近端说话声音的时候会造成无声;若没爆音,则根据aec_state.ErleUncertainty()得到erle_uncertainty,对于爆音情况下来说,erle_uncertainty=1.0f(但是我感觉有了前面那个条件,这里也不可能走到这个分支啊,存疑),否则的话erle_uncertainty为nullpot。然后就开始估计了,对于爆音情况下,使用S2_linear和1.0f来计算得到R2,对于其他情况下,则使用S2_linear和计算出来的Erle来估计R2。
下面重点讲一下使用线性处理结果估计R2的函数LinearEstimate,其本质上是一样的实现,只不过一个里面erle的一项为固定的float数据,另一个就是erle的数组了,所以这里讲解我都以通用形式的输入参数为S2_linear、erle来解释。它的计算过程就是对于每一个通道ch,对于每一个频点k,R2[ch][k] = S2_linear[ch][k] / erle[ch][k]。在完成这些操作之后,将混响的估计功率添加到残余回声功率,至此R2计算初步完成。
2.若不适用线性处理的结果来做残余回声估计。则执行下面的步骤:
第一步是执行GetEchoPathGain得到echo_path_gain。若是透传模式,则gain_amplitude=0.01,否则为config的默认值,然后返回gain_amplitude*gain_amplitude。
第二步依旧是判断是否爆音,若爆音则残余回声估计就是参考信号;否则的话,估计回声产生信号功率(将回声生成信号功率估计为一个时间窗口内的门控最大功率)X2,若不用平稳特性,则对回声产生功率应用软噪声门限,然后减去静态噪声功率以避免静态噪声导致过度的回声抑制得到最终的X2,然后使用NonLinearEstimate估计R2,如果是非透传模式,则在R2加上混响。
第三步,如果使用平稳特性的话,则根据回声可听度缩放回声。
流程图如下:
非线性处理也是分为低频带和高频带。
对于低频带,其处理位于LowerBandGain()函数中,首先让gain全部置1,通过限制先前增益的增益增加来计算最大增益。然后对于每一个通道来说,将线性输出求解平均,保存在nearend中。然后以可懂度为条件来加权前面计算出来的残余回声得到weighted_residual_echo,然后使用加权后的残余回声、上一帧近端、上一帧回声、low_noise_render计算得到min_gain【仅在爆音情况下更新,否则为0】。最后的关键就是计算增益。
增益的计算过程如下:对于每一个频点来说,首先计算ENR(估计的残余回声能力与线性滤波器输出能力的比值)和EMR(回声能量与舒适噪声能量的比值)。然后如果enr大于一个门限值且emr大于一个门限值的话,增益gain为(p.enr_suppress_[k]-ENR)/(p.enr_suppress_[k] - p.enr_transparent_[k])和p.emr_transparent_[k] / emr两者的最大值。p.enr_suppress_是ENR的一个较小门限,enr_transparent_是一个较大门限。emr_transparent_ / emr是抑制到底噪水平对应的gain, voip场景可以不保留底噪。 这种简单计算目前发现的问题是信噪比低时容易剪切,非线性失真较严重时回声消得不太干净。
计算完增益就是对其进行一些限制,避免出现问题。
至此,整个AEC3的初步分析到这里结束了。分析很粗略,很多东西还不清楚,需要实践一步一步有更深的思考。由于博客格式问题较多,想更好的学习或者有什么问题,欢迎到飞书文档进行浏览和留言。点击这里:飞书文档链接: https://qouwscohey.feishu.cn/docs/doccnUcSGDg8ehjisuw1ww5KmGi,访问密码可通过关注我的公众号,并回复“AEC3”获得。



文章评论
gain_change_hangover_ 应该是每三个block 只能够调整一次,这样保证每帧只调整一次,至于为什么3块能够保证一帧,还没有想明白