摘要
本文介绍了一款名为WeNet的开源端到端语音识别工具包。其核心创新在于提出 “U2” 架构,首次在单一模型中统一了流式(实时)与非流式(离线)的语音识别模式,旨在弥合前沿研究模型与实际工业部署之间的差距。
核心问题与目标:解决端到端语音识别模型研究与部署脱节的问题,提供一个生产就绪、高效率的解决方案。
核心技术(U2):
-
模型架构:采用混合CTC/注意力机制,以Transformer或Conformer作为编码器,并用注意力解码器进行重打分以提升精度。
-
关键创新(动态分块注意力):通过动态分块策略,使自注意力能灵活控制右文视野。这是实现单一模型同时支持流式与非流式的关键——流式时使用有限右文,非流式时使用全部右文。
引言
目前ASR在工业部署存在以下问题:
-
流式推理的困难:许多先进的端到端模型(如LAS、Transformer)原生不支持流式处理,强行改造往往导致性能下降或工程复杂度激增。
-
模式统一的必要性:为流式(实时)和非流式(离线)场景分别开发和维护两套模型,成本高昂、效率低下。业界迫切需要能在一个模型中动态切换或兼顾两种模式的解决方案。
-
生产部署的复杂性:这是阻碍端到端模型落地的最大挑战,主要体现在:
-
推理流程复杂:自回归解码(如束搜索)导致推理逻辑冗长,优化困难。
-
资源约束苛刻:在边缘设备上部署需精细权衡计算速度与内存占用。
-
平台选择专业性强:面对众多推理框架(ONNX、TensorRT等),需同时精通语音业务与底层深度学习优化才能做出最佳选择,技术门槛高。
-
核心矛盾:端到端模型在学术指标(如词错误率)上已表现出优势,但其在生产落地时,在实时性、统一性和工程易用性方面仍存在显著鸿沟。 WeNet的设计正是为了系统性地解决这三大问题。
因此,作者提出了Wenet。
-
根本定位:WeNet是以生产部署为核心导向的端到端语音识别工具包,旨在打通从学术研究到工业落地的全链路。
-
核心技术:提出 U2 双通框架,这是实现流式与非流式模式在单一模型中统一的关键创新。
-
核心优势:
-
生产无缝衔接:依托PyTorch生态(TorchScript/JIT),实现训练到部署的无缝转换,消除模型转换代价。
-
工业友好:提供统一的流式/非流式模型,降低企业开发与维护成本。
-
多平台覆盖:提供从服务器到嵌入式设备的便携式运行时,展示实际部署方案。
-
极简依赖:完全基于PyTorch,摒弃对Kaldi等复杂工具的依赖,使安装和使用极其简单。
-
-
最终目标:打造一个代码简洁、易于学习、且具备完整生产流程的语音识别工具包,推动端到端技术的实际应用。
Wenet架构
模型结构
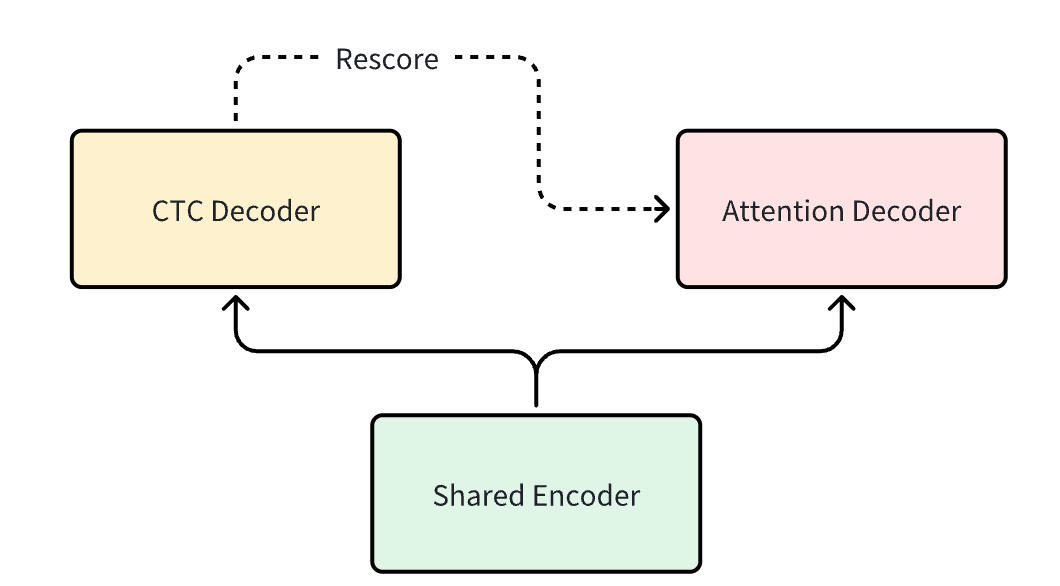
如前面所述,该方案旨在解决流式处理、模式统一与生产部署三大问题,为此所构建的解决方案必须兼顾简洁性、易构建性、运行时便捷性,同时保持优异性能。
U2作为一种统一的双通联合CTC/注意力编解码器(Attention based Encoder and Decoder, AED——模型,为此提供了优秀解决方案。如图1所示,U2由三个部分组成:共享编码器、CTC解码器与注意力解码器。共享编码器由多个Transformer或Conformer层构成,其设计仅纳入有限的右文语境,以维持均衡的延迟表现。CTC解码器包含一个线性层,负责将共享编码器的输出转换为CTC激活值;而注意力解码器则由多个Transformer解码器层组成。在解码过程中,CTC解码器在第一通以流式模式运行,随后注意力解码器在第二通介入,以提供更精准的识别结果。
训练
在U2结构训练的时候,作者对CTC和注意力编解码器的损失函数进行组合,即
其中,x是声学特征,y是对应的标签, lambda是一个平衡CTC损失与注意力编解码器损失重要性的超参数。
如前所述,当共享编码器无需完整语音信息时,U2模型可在流式模式下工作。作者采用了一种动态分块训练技术来实现非流式与流式模型的统一。具体实现方式如下:
首先,输入语音按固定分块大小C被划分为若干片段(每个片段包含输入[t+1, t+2,…,t+C]),每个片段仅关注自身及之前所有片段的信息。因此,第一通CTC解码器的整体延迟完全取决于分块大小C。当分块大小受限时,模型以流式方式工作;反之则以非流式方式工作。
其次,在训练过程中,分块大小会动态变化——从1到当前训练语句的最大长度随机取值。通过这种设计,训练得到的模型能够适应任意分块大小的预测需求。
根据经验,较大的分块尺寸会带来更高的识别精度,但也会增加延迟。因此在实际运行时,可通过调整分块尺寸来灵活权衡识别准确率与延迟表现。
解码
在研究阶段基于Python的解码过程中,为对比和评估联合CTC/注意力编解码器模型的不同组成部分,WeNet支持以下四种解码模式:
-
attention(注意力解码):对模型的注意力编解码器部分应用标准的自回归束搜索。
-
ctc_greedy_search(CTC贪心搜索):对模型的CTC部分应用CTC贪心搜索,此模式速度远超其他模式。
-
ctc_prefix_beam_search(CTC前缀束搜索):对模型的CTC部分应用CTC前缀束搜索,可生成n个最优候选序列。
-
attention_rescoring(注意力重打分):首先对模型的CTC部分应用CTC前缀束搜索生成n个最优候选序列,随后利用对应的编码器输出,通过注意力解码器部分对这些候选序列进行重打分。
在开发与运行阶段,WeNet仅支持attention_rescoring(注意力重打分)解码模式。
注意力解码:
这是纯注意力编解码器模型(如LAS、标准Transformer)的标准解码方式,完全依赖其内部的注意力机制和自回归语言模型。
-
工作原理:
-
编码器处理完整个音频,输出完整的上下文向量序列。
-
解码器启动,起始符
<sos>作为第一个输入。 -
解码器利用交叉注意力查看编码器的全部输出,并结合自身的自注意力处理已生成的词,预测下一个词的概率分布。
-
使用束搜索来管理多个候选序列,选择整体概率最高的序列作为最终输出。
-
CTC贪心搜索:
这是纯CTC模型最简单、最快速的解码方式,不依赖任何外部或内部的语言模型。
-
工作原理:
-
编码器逐帧(或在分块内)前向计算。
-
在每一时间步,模型输出一个概率分布(覆盖所有字符和
<blank>)。 -
贪心策略:直接取每个时间步概率最高的字符。
-
最后应用CTC规则:合并重复字符,删除所有
<blank>,得到最终文本。 -
示例:帧级输出
[-, 你, 你, -, 好, 好, 好]-> 合并重复 ->[你, 好]-> 删除-->“你好”。
-
CTC前缀束搜索:
这是CTC模型的高精度解码方法,引入了有限的语言模型整合和搜索空间。
-
工作原理:
-
同样,编码器输出每一帧的概率分布。
-
它不是贪心选择,而是维护一个束宽大小的候选序列集合。
-
在每一时间步,将现有候选序列与当前帧的可能输出进行扩展。
-
关键点:它会在去重和删空后的“前缀”级别上进行分数合并和排序,防止搜索空间爆炸,并可以整合一个外部语言模型(如n-gram或神经网络LM)的分数。
-
最终,返回n个(束宽大小)最优的候选序列。
-
注意力重打分:
这是联合CTC/AED模型(如WeNet U2)的生产级解决方案,巧妙结合了CTC和Attention的优点。
-
工作原理(两阶段解码):
-
第一阶段(CTC快速初选):
-
使用CTC Prefix Beam Search快速生成一个n-best候选列表(例如10或20条)。这一步可以流式进行(分块处理),速度快,延迟可控。
-
-
第二阶段(AED精准重打分):
-
将第一阶段产生的每条候选序列,以及对应的完整编码器输出(此时音频已全部处理完毕),送入注意力解码器。
-
注意力解码器以该候选序列为输入,计算其对数似然分数。这个过程利用了注意力机制强大的全局上下文建模和内部语言模型能力。
-
将CTC分数和注意力重打分分数按一定权重(如
logP = λ * logP_ctc + (1-λ) * logP_att)结合,选择总分最高的候选作为最终输出。
-
-
| 解码模式 | 核心原理 | 优点 | 缺点 | 适用场景 |
| Attention | 纯AED自回归束搜索 | 理论精度高 | 延迟极高、速度慢、非流式 | 纯AED模型研究、非实时离线识别 |
| CTC Greedy | CTC逐帧取最大概率 | 速度最快、极低延迟、天然流式 | 精度最低、无语言模型 | 对实时性要求极高、对精度要求不严的流式场景 |
| CTC Prefix Beam | CTC束搜索+外部LM | 精度优于贪心、支持流式、提供n-best | 速度慢于贪心、精度有天花板 | 纯CTC模型生产、或作为注意力重打分的第一阶段 |
| Attention Rescoring | CTC初选 + AED重打分 | 精度与效率的最佳平衡、生产友好、支持统一流式/非流式 | 总体计算量最大 | 联合CTC/AED模型的生产部署 |
系统设计
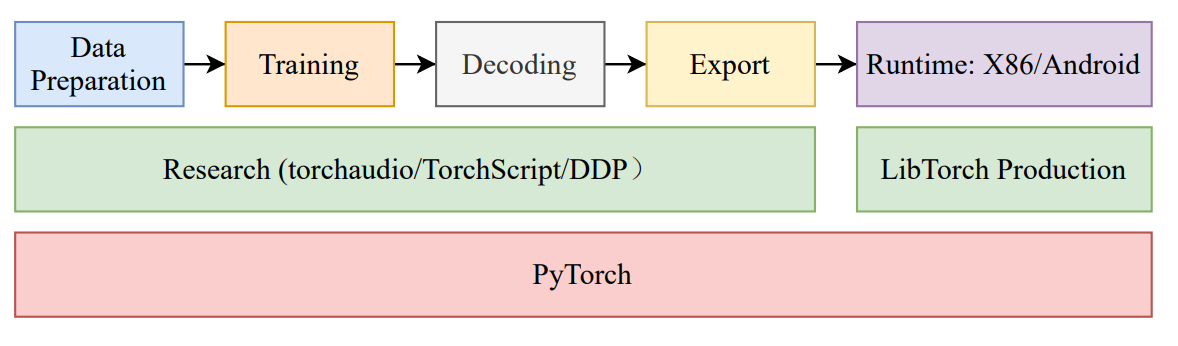
WeNet的整体设计栈如上图所示。值得注意的是,其底层架构完全基于PyTorch及其生态系统。中间层由两部分组成:在研究模型开发阶段,使用TorchScript进行模型开发,通过Torchaudio实现实时特征提取,借助分布式数据并行技术进行分布式训练,利用PyTorch即时编译完成模型导出,采用PyTorch量化工具压缩模型,并最终通过LibTorch实现生产环境运行时部署。LibTorch生产运行时专门用于部署生产模型,其设计支持多种硬件与平台,包括CPU、GPU(CUDA)、Linux、Android及iOS系统。顶层展示了WeNet中典型的研究到生产全流程管线。接下来详细介绍具体各模块具体设计。
数据准备
由于在训练中采用了实时特征提取技术,在数据准备阶段无需进行任何离线特征提取。WeNet仅需一份Kaldi格式的文本转录、一个音频文件列表以及一个模型单元字典,即可生成所需的输入文件。
训练
WeNet训练阶段具有以下关键特性:
实时特征提取:该功能基于Torchaudio实现,可生成与Kaldi相同的梅尔滤波器组特征。由于特征直接从原始PCM数据实时提取,WeNet能够在时域和频域层面对原始PCM数据同时进行数据增强,并最终在特征层面同步处理,从而显著提升数据的多样性。
联合CTC/注意力编解码器训练:联合训练不仅加速了训练收敛过程,还提升了训练稳定性,并最终带来更优的识别效果。
分布式训练:WeNet支持通过PyTorch的DistributedDataParallel进行多GPU训练,以充分利用多节点多GPU资源,实现更高的线性加速比。
解码
作者提供了一套Python工具,可用于识别音频文件并在不同解码模式下计算准确率。这些工具帮助用户在将模型部署到生产环境前进行验证和调试。第2.1.2节中提到的所有解码算法均受支持。
模型导出
由于WeNet模型通过TorchScript实现,可直接通过PyTorch即时编译安全地导出至生产环境。随后,导出的模型可在运行时借助LibTorch库进行部署,同时支持浮点32位模型和量化8位整型模型。在嵌入式设备(如基于ARM架构的Android与iOS平台)上部署时,使用量化模型可使推理速度提升一倍甚至更多。
更多内容,可以访问:飞书 Docs Link: https://my.feishu.cn/docx/LrICdA2h9oJHnvxR2qYcxhwNnNb Password: 1646&54s



文章评论