计算噪声功率谱程序(WebRtcNs_AnalyzeCore)
计算信噪比函数之前的部分分别是:
1.对输入的时域帧数据进行加窗、FFT变换。
2.然后计算能量,若能量为0,返回;否则继续往下。
3.然后计算新的能量和幅度。
4.使用分位数噪声估计进行初始噪声估计。
5.然后取前50个帧,计算得到高斯白噪声、粉红噪声模型,联合白噪声、粉红噪声模型,得到建模的混合噪声模型。
计算信噪比(ComputeSnr)
作用:根据分位数噪声估计计算前后信噪比
Inputs:
|magn|.信号幅度谱估计
|noise| 噪声幅度谱估计
Outputs:
|snrLocPrior|先验SNR
|snrLocPost| 后验SNR
后验信噪比指观测到的能量与噪声功率相关的输入功率相比的瞬态SNR:
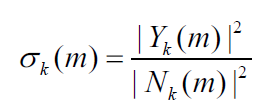
其中Y是输入含噪声的频谱, N是噪声频谱,先验SNR是与噪声功率相关的纯净(未必是语音)信号功率的期望值,可表示为:
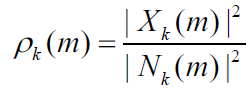
其中X是指输入的纯净信号,这里对应的指语音信号。在WebRTC实际的计算中,并没有采用平方数量级,而是采用了量级数量级。
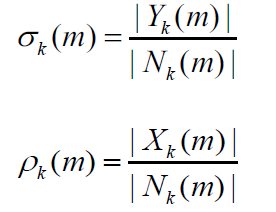
由于纯净信号是未知信号,先验SNR的估计是上一帧经估计的先验SNR和瞬态SNR的平均值:
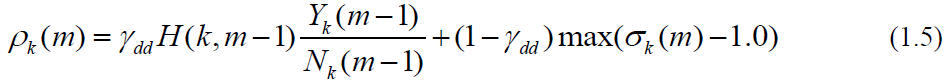
上式中H对应与代码中的smooth是上一帧的维纳滤波器,用于对瞬时SNR平滑,前一项是上一帧的先验SNR,后一项是先验SNR的瞬态估计。其通过判决引导DD进行跟新,时间平滑参数是 ,其值越大,流畅度越高,延迟也会越大,程序中选择的是0.98。
特征提取(FeatureUpdate)
作用:提取平均LRT参数、频谱差异、频谱平坦度
Inputs:
// * |magn| is the signal magnitude spectrum estimate.
// * |updateParsFlag| is an update flag for parameters.
计算频谱平坦度(ComputeSpectralFlatness)
作用:频谱平坦度计算。
原理:该算法假设语音比噪声有更多的谐波。语音频谱往往会在基频(基音)和谐波中出现峰值,而噪声频谱则相对平坦。因此其作为区分噪声和语音的一个特征。
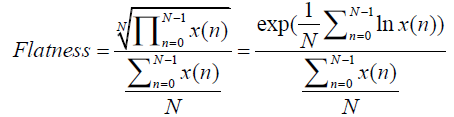
频谱度计算时N表示STFT后频率点数,B代表频率带的数量,K是频点指数,j是频带指数。每个频带包括大量的频率点。就128个频率点可分成4个频带(低带,中低频带,中高频带,高频),每个频带32个频点。对于噪声Flatness偏大且为常数,而对于语音,计算出的数量则偏下且为变量。
根据上面的公式,如果接近于1,则是噪声,(噪声的幅度谱趋于平坦),二对于语音,上面的N次根是对乘积结果进行N次缩小,相比于分母部分,缩小的数量级是倍数的,所以语音的平坦度较小,是趋近于0的。
计算频谱差异度(ComputeSpectralDifference)
作用:计算输入谱模板(学习到的)噪声谱的差异程度。所参考的噪声谱是self->magnAvgPause[i],返回值是正则化的频谱差异,为self->featureData[4]。
除了频谱平坦度特征的噪声相关假设之外,有关噪声频谱的另一个假设是,噪声频谱比语音频谱更稳定。因此,可假设噪声频谱的整体形状在任何给定阶段都倾向与保持相同。模板频谱通过更新频谱(最初被设为零)中极有可能是噪声或语音停顿的区段来确定。该比较结果是对噪声的保守估计,其中仅对语音概率确定低于阈值(如 的区段处跟新了噪声。在其它分布中,模板频谱也可能被导入到算法中,或从对应不同噪声的形状中筛选出来。考虑到输入频谱 和模板频谱(表示为 ),如想获得频谱模板差异特征,可首先将频谱差异测量定义为 ,其中α和u是形状参数,包括线性位移和振幅参数,是通过将J最小化获得的。(α,u) 通过线性方程获得,因此可对每个帧轻松抽取此参数。在某些示例中,这些参数可表明输入频谱(在音量增加的情况下)的任何简单位移/标度变化。之后该特征将成为标准话的测度。
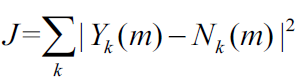
语音噪声概率更新(SpeechNoiseProb)
作用:计算语音/噪声概率,存储在probSpeechFinal。
magn:输入幅度谱。noise:噪声谱
理论基础
先推导语音/噪声概率计算方法,先来看语音/噪声的概率模型,定义语音状态为 ,定义噪声状态为 ,其中m是帧,k是频率,则语音/噪声的概率可以表示为: 。这一概率取决于观测到的额噪声输入频谱系数 以及所处理信号的一些特征数据(如信号的分类特征),也就是这里的{F}。特征数据可以是有噪输入频谱,过往频谱数据,模型数据等。如特征数据{F}可以包括频谱平坦度测量,谐振峰值距,LPC残余以及模板匹配等。根据贝叶斯准则,语音/噪声概率可表示为:
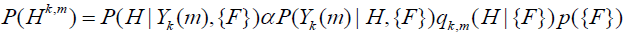
其中 是以信号的特征数据为基础的先验概率,该值在后续中被设为一个常数。 是特征数据 下的语音/噪声概率,在忽略 为基础的先验概率p{F},简化语音概率和噪声概率为:
语音概率: ,噪声概率 ,这样标准化的语音概率可以写为:



LRT均值的计算
前面计算了三个特征中的两个(频谱差异度和频谱平坦度),这里介绍第三个,也就是LRT均值,这也是这个函数代码最开始的部分。实际上在理论里面已经把LRT均值的计算理论公式给出,但是有时候帧与帧之间的频变似然比因子 会有很大波动,所以采用经过时间平滑处理的似然比因子:
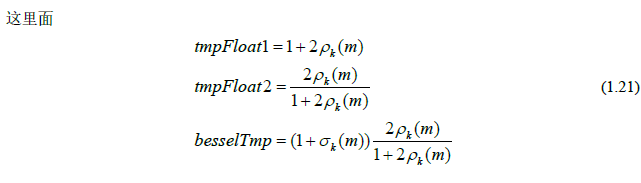

LRT均值同时也作为q公式的参数之一,用来计算q。
q的计算
q的数值依赖于LRT均值、频谱差异度、频谱平坦度。
在语音/噪声概率计算时,使用高斯假设作为语音PDF模型,从而获得似然比。在其它模型中,概率密度PDF模型也可以用作测量似然比的基础,包括拉普拉斯算子,伽马,超高斯。举个例子,当高斯假设可合理表示噪声时,该假设并不一定适用于语音,尤其是在较短的时帧中(如~10ms)。在这种情况下,可以使用另一种语音PDF模型,但这很可能会增加复杂性。
要在噪声估计和过滤流程中确定语音/噪声的概率,这不仅需要本地SNR(即先验SNR和瞬态SNR)的引导,还要结合从特征建模中获得的语音模型/认知内容。将语音模型/认知内容并入到语音/噪声概率确定中,能让噪声抑制流程更好地处理和区分极不稳定的噪声水平。如果仅依靠本地SNR,可能会造成可能性偏差。这里对包含本地SNR和语音特征/模型

gainPrior = ((float)1.0 - inst->priorSpeechProb) / (inst->priorSpeechProb + (float)0.0001);
for (i = 0; i < inst->magnLen; i++) {
invLrt = (float)exp(-inst->logLrtTimeAvg[i]);
invLrt = (float)gainPrior * invLrt;
probSpeechFinal[i] = (float)1.0 / ((float)1.0 + invLrt);
}
更新噪声估计(UpdateNoiseEstimate)
功能:更新噪声估计
输入:magn、snrLocPrior、snrLocPost
输出:noise:更新的噪声频谱估计
的平滑度。这个式子是使用了输入频谱和上次噪声估计的值对噪声进行估计,它的估计方法是这样的:当处于噪声可能性比较大的帧和频率槽的时候,进行更新;如果是语音可能性比较大的时候,就用上一个帧的估计作为噪声估计。
噪声估计更新流程受到语音/噪声概率和平滑参数γ控制。对于语音概率超过阈值参数的地方,平滑参数可能会被增加到0.99,以防止语音开始处的噪声水平增加过高。
处理核心程序(WebRtcNs_ ProcessCore)
- 确定高低频。
- 加窗,计算带噪语音数据帧能量,同样若能量为0,那么进行特殊处理。
- 进行FFT变换。
- 基于引导更新计算维纳滤波器的系数。ComputeDdBasedWienerFilter(self, magn,
theFilter);计算公式见公式(1.5)。 - 对维纳增益值根据用户设置的降噪等级进行下溢和上溢处理
- 进行维纳滤波,然后将频域数据(频率降噪)通过IFFT转为时域数据
- 对降噪等级进行判断,如果等级为0,则维纳滤波输出则为最后的降噪结果。否则,到第8步。
- 再来计算维纳滤波后每一帧的数据能量,然后与前面的能量做比值得到gain=sqrtf(energy2 /
(energy1 + 1.f)); - 计算factor1和factor2。
- 结合Analyze中的priorSpeechProb计算最终的增益因子:factor = self->priorSpeechProb *
factor1+(1.f - self->priorSpeechProb) * factor2; - 数据相乘,得到降噪结果:self->syntBuf[i] += factor * winData[i];
此文章为个人学习笔记整理所得,所有截图均为个人整理的笔记中的截图。如有转载,敬请注明。下一期将更新关于WebRTC中VAD(语音活动检测)的学习笔记,敬请期待。



文章评论
写的挺好的,谢谢分享
大神最近有没有在研究webRTC的Ns模块,我下载的最新版代码发现Ns的变化好大,跟结构大不一样,而且完全变成C++ :???:
@匿名 webRTC里面的NS本身我记得就是在C++里面呀
@匿名 到没有看webrtc的代码。现在主要在看我们公司的代码了。。。只是偶尔看一看webrtc的东西。。。