
待完善
Deep Learning
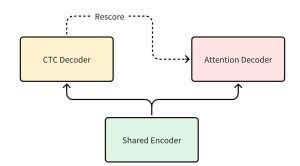
WeNet: Production Oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit
摘要 本文介绍了一款名为WeNet的开源端到端语音识别工具包。其核心创新在于提出 “U2” 架构,首次在单一模型中统一了流式(实时)与非流式(离线)的语音识别模式,旨在弥合前沿研究模型与实际工业部署之间的差距。 核心问题与目标:解决端到端语音识别模型研究与部署脱节的问题,提供一个生产就绪、高效率的解决方案。 核心技术(U2): 模型架构:采用混合CTC/注意力机制,以Transformer或Conformer作为编码器,并用注意力解码器进行重打分以提升精度。 关键创新(动态分块注意力):通过动态分块策略,使自注意力…

摘要 传统方法通常使用时频掩码(TF mask)对含噪频谱图进行点乘处理,而复数值掩码(CM)因其能修正相位而优于时值掩码。近期很多研究提出使用复数值滤波器代替掩码点乘操作,通过利用频带内局部时间相关性,整合过去和未来时间步的信息。 这篇论文提出了DeepFilterNet,是一种基于深度滤波的两阶段语音增强框架。第一阶段利用ERB(等效矩形带宽)缩放的增益增强语音的频谱包络,模拟人耳听觉的频率感知特性;第二阶段通过深度滤波增强语音的周期性成分,除了利用语音的感知特性外,还通过可分离卷积和线性层/循环层中的分组策略…
信号模型 假设输入信号为: 【待本周末更新】 大家可以临时先看:飞书链接:https://qouwscohey.feishu.cn/docx/EeDSdR09Bo9QuWx04RIcHNBfnke 密码可以关注我的公众号“小奥的学习笔记”(也可以扫右侧的码)关注后,回复“GKF”或者“gkf”即可获得密码。

参考视频:https://space.bilibili.com/230105574/ 阅读原文请访问:https://qouwscohey.feishu.cn/docs/doccnAtfHvdvbQZzj5YfXWX8Etd 第一节:递归算法 不确定性:①不存在完美的数学模型;②系统的扰动不可控,也很难建模;③测量传感器存在误差。 我们可以发现,随着k增大,1/k趋近于0,那么xk->xk-1。也就是说,随着k增加,测量结果不再重要。而k越小,1/k越大,zk的作用越大。 如果我们把1/k用一个参数Kk来代替…

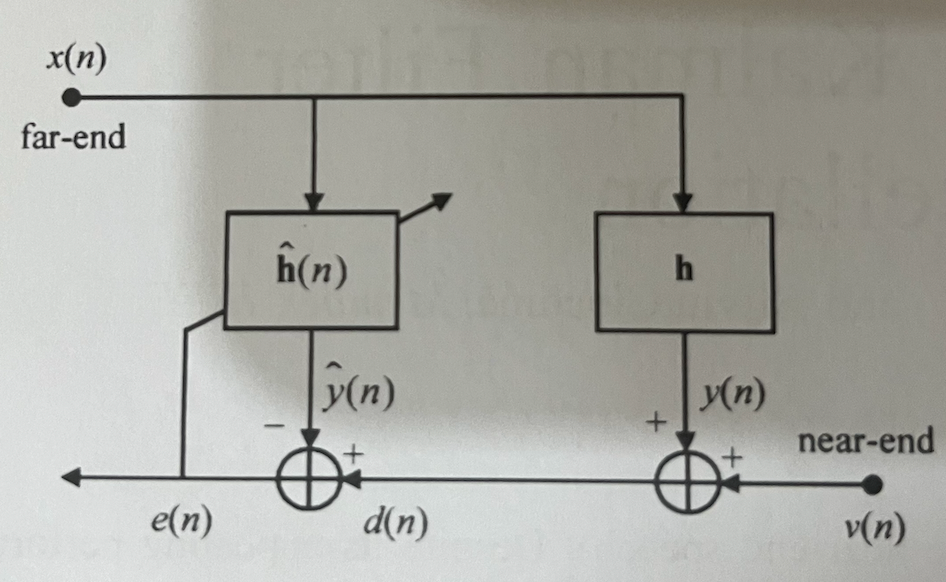
计算参考信号和采集信号的时延:GetDelay() AEC3中的时延估计算法是使用计算滤波器能量最大块来作为延迟估计值,它是当滤波器收敛到一定程度时,计算所有滤波器系数的能量,取峰值的系数(tap)对应的delay就是对齐需要的delay。它是由步长为0.7的5个时域的NLMS滤波器组成,每个滤波器默认为32个块,每个块有16个样点,总计有32*16=512个样点,5个滤波器理论上共有512*5=2560个点,但实际上5个滤波器在时域上互相重叠8块(即输入的信号在时间上存在重叠),所以实际上5个滤波器可以估计256…

整体框图 参考信号:送往时延估计、AEC的状态计算 采集信号:送往时延估计、线性滤波器、AEC的状态计算 线性滤波器使用时延对齐后的参考信号和采集信号进行处理;线性滤波器处理后的结果送往NLP模块,最终得到处理结果。 类调用关系图 EchoCanceller3(入口) AnalyzeRender 该部分只是将AudioBuffer类型的参考信号insert到render_transfer_queue_,这是一个swapqueue,数据从结尾insert,从开头remove,这里没有什么可以说的【当然insert之前…

最近评论
davidcheung 发布于 1 年前(02月09日)
tk88 发布于 1 年前(02月07日)
cuicui 发布于 2 年前(10月20日)
niming 发布于 2 年前(09月19日)
davidcheung 发布于 3 年前(08月16日)
Nolan 发布于 3 年前(07月25日)
davidcheung 发布于 4 年前(06月19日)
aobai 发布于 4 年前(03月13日)
匿名 发布于 5 年前(12月30日)
小奥 发布于 6 年前(12月12日)