
待完善
Deep Learning
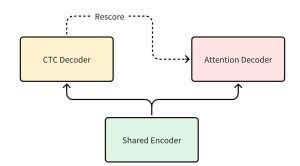
WeNet: Production Oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit
摘要 本文介绍了一款名为WeNet的开源端到端语音识别工具包。其核心创新在于提出 “U2” 架构,首次在单一模型中统一了流式(实时)与非流式(离线)的语音识别模式,旨在弥合前沿研究模型与实际工业部署之间的差距。 核心问题与目标:解决端到端语音识别模型研究与部署脱节的问题,提供一个生产就绪、高效率的解决方案。 核心技术(U2): 模型架构:采用混合CTC/注意力机制,以Transformer或Conformer作为编码器,并用注意力解码器进行重打分以提升精度。 关键创新(动态分块注意力):通过动态分块策略,使自注意力…

摘要 传统方法通常使用时频掩码(TF mask)对含噪频谱图进行点乘处理,而复数值掩码(CM)因其能修正相位而优于时值掩码。近期很多研究提出使用复数值滤波器代替掩码点乘操作,通过利用频带内局部时间相关性,整合过去和未来时间步的信息。 这篇论文提出了DeepFilterNet,是一种基于深度滤波的两阶段语音增强框架。第一阶段利用ERB(等效矩形带宽)缩放的增益增强语音的频谱包络,模拟人耳听觉的频率感知特性;第二阶段通过深度滤波增强语音的周期性成分,除了利用语音的感知特性外,还通过可分离卷积和线性层/循环层中的分组策略…

第三周:序列模型和注意力机制 3.1 基础模型 1.序列到序列模型 【参考文献:Sutskever et. al., 2014. Sequence to sequence learning with neural networks, Cho et. al., 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation】 如图1所示,那么怎样训练处一个网络来输入序列x和输出序列y…

Project 5 Week3 自然语言处理与词汇嵌入 1 词汇表征 1. One-hot表征 one-hot表征的方式是对模型字典中的单词进行表征,对应单词的位置用1表示,其余位置用0表示,如图1所示: 图1 这种方法是存在缺点的,它将每个词孤立起来,使得模型对相关词的泛化能力不强,每个词向量之间的距离都一样,乘积均为0,所以无法获取词与词之间的相似性和关联性。 2.特征表征:词嵌入 这种方法是用不同的特征来对词汇进行表示,不同的单词在不同的特征下都有不同的取值,取值可以表示该词汇在该特征下的相似度…

序列模型 1. Why sequence models? 在实际的生活中,很多东西都是序列信号,例如语音信号、音乐产生、情感分类、DNA序列分析等,这些虽然可以使用一般神经网络去完成,但就如同图像识别一样,那样去做太过于复杂,因此在这里引入了循环神经网络(RNN)。 2. Notation x:代表输入的语句,例如:Harry Potter and Herminone Granger invented a new spell.并且使用x<t>代表本句中第t个单词。 y:代表输出结果。例如上句中对人名进行…

特殊应用:人脸识别和神经风格迁移 1.人脸识别(Face Recognition) 人脸识别包括两个部分: (1)验证(Verification) 输入图像,名字/ID;输出所输入的图像是不是所要验证的那个人。 (2)识别(Recognition) l 拥有K个人的数据库。 l 得到一个输入图像。 l 如果输入图像是这K个人之一,输出ID;否则的话,输出“未识别”。 人脸识别问题相对于人脸验证来说具有更高难度。对于一个验证系统来说,如果拥有99%的精确度,则这个系统已经有很高的精…

最近评论
davidcheung 发布于 1 年前(02月09日)
tk88 发布于 1 年前(02月07日)
cuicui 发布于 2 年前(10月20日)
niming 发布于 2 年前(09月19日)
davidcheung 发布于 3 年前(08月16日)
Nolan 发布于 3 年前(07月25日)
davidcheung 发布于 4 年前(06月19日)
aobai 发布于 4 年前(03月13日)
匿名 发布于 6 年前(12月30日)
小奥 发布于 6 年前(12月12日)