语音和阵列信号的基础
以下内容均为自己有关文献和论文整理,因为部分公式较难打出,所以整理成了图片。
语音信号及特点
1.语音信号的几大特点:

噪声场
不同噪声场中的噪声之间的相关程度不一样。定义噪声相关函数如下:
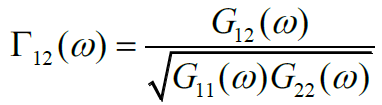

一般认为,在不考虑噪声的散射、幅度衰减等的情况下,相干噪声场中噪声直达各个麦克风。实际中,开放的、没有混响的环境通常为相干噪声场;非相干噪声场中,噪声互不相干,理想的非相干噪声场实际环境很少见,通常认为麦克风产生的电子噪声为非相干噪声。许多实际噪声环境可以看作散射场,如室内、车内环境等。
近场和远场
| 区分 | 特点 | |
|---|---|---|
| 远场 | 一般认为信源到阵列中心的距离远大于信号波长为远场 | 声音信号是平面波,阵列接收的多路信号间主要存在时延差,忽略它们的幅度差。 |
| 近场 | 反之为近场。 | 考虑阵元接收信号间的幅度差,认为声音信号是球面波。 |
空间采样定理
对于阵元间距相等的线性阵列来说,定义空间采样频率为

宽带信号接收模型
假设空间中有一个M阵列的阵元,接收到一个直达的宽带信号,入射角为θ,那么第m个阵元接收到的信号可以表示为
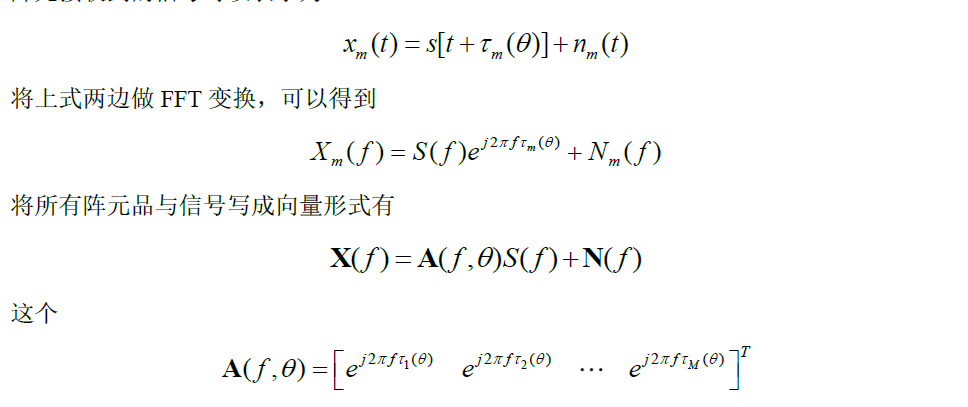
就是导向矢量,其与信号频率和试验有关系,时延又和阵列结构以及入射角有关系。
接下来的内容可以将频域的窄带波束形成算法扩展到宽带。
如果我们将信号观察期间内接收到的数据进行分块,对每块信号进行K点变换,只要数据块比信号相关事件长,那么变换后的每块数据都不想管,那么向量形式的公式可以转化为短时分析的形式
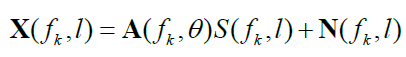
式中分别是第l数据块的接受信号、第一个麦克风接收的源信号、噪声在fk处的DFT。fk是第k个频点对应的频率。
导向矢量估计
导向矢量估计主要有以下几种方法:
1. 直接估计导向矢量。这一类方法基于这一准则:期望信号相关矩阵的特征向量可以作为导向矢量的估计,估计出相关矩阵后进行广义特征值分解,找到最大特征值对应的特征向量,认为是导向矢量的估计。
2. 时延估计。这是一种间接估计导向矢量的方法,得到每个麦克风相对参考阵元的时延后,便可计算出每个频率分量对应的导向矢量,时延估计更为简单,对于需要时间同步的算法,也更为直接。环境混响程度轻、信噪比高条件下,现有的时延估计算法能取得良好性能,但在低信噪比复杂环境下,鲁棒性不高,性能下降,而波束形成算法的同步操作对时延误差比较敏感。使用麦克风阵列进行语音增强,而不涉及其他需求(声源跟踪、定位等),计算时延是较为直接的导向矢量估计方法。
3. 声学传递函数ATF估计。
4. 波达方向估计。时延估计与DOA估计是等价问题,两者可以相互转换:DOA估计出信号入射角度后,在已知阵列结构条件下,便可计算出各阵元的相对时延,进而得到导向矢量。基于DOA的方法,理想情况下性能好,通常考虑信号为直达声,信噪比低、环境混响严重时,DOA性能急剧下降,另外阵列结构信息在有些运用中是未知的。尽管 DOA算法在实际中有较多运用,但在导向矢量估计方面并没有时延估计那么直接。
后置滤波
后置滤波原因:
1. 波束形成对于非相干噪声去除能力较差;
2. 波束形成对于非稳态噪声处理能力有限。
后置滤波器的参数需要利用多路输入信号的信息来计算,可以进一步抑制波束形成输出的噪声,解决波束形成对非相干噪声抑制能力不足的问题,提高语音增强算法的性能。
Zelinski方法的维纳滤波器表达式如下:
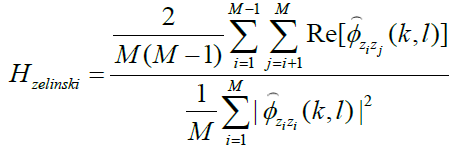
上面Re后面的式子和下面那个式子分别表示相位同步之后的输入信号的互功率谱的估计和自功率谱的估计。整个方法的意思是:用阵列得到的多路信号的自相关和互相关功率谱密度的平均,来估计波束形成输出信号中的期望信号和噪声的功率谱。
这个方法存在两个问题:
- 如果噪声信号相关性较大,噪声功率就会欠估计,噪声去除不足。
- 如果噪声相关性较低,就会过估计,导致信号的失真。
所以在实际的散射场中,会存在低频去噪能力不足,有残留噪声。这是因为噪声往往在低频具有较高的相关性。
参考文献
[1] 张丽艳. 复杂环境下麦克风阵列语音增强方法研究[D]. 大连理工大学, 2009.
[2] 何礼, 周翊, 刘宏清. 利用相位时频掩蔽的麦克风阵列噪声消除方法[J]. 信号处理, 2018, 34(12):100-108.
[3] Cohen I . Relative Transfer Function Identification Using Speech Signals[J]. IEEE Transactions on Speech and Audio Processing, 2004, 12(5):451-459.



文章评论