前段时间阅读了一片来自于德国Carl von Ossietzky Universität Oldenburg的Jörn Anemüller和Hendrik Kayser的一篇论文,论文名字叫做《Multi-channel signal enhancement with speech and noise covariance estimates computed by a probabilistic localization model》,看完感觉还挺有借鉴意义的,所以做一个总结。
论文所提方法和旧方法的比较
这篇文章提出了一种麦克风阵列语音增强的算法,这种算法也是基于传统MVDR算法改进而来,因为它采用了新的方式来估计所用的参数,所以效果相比传统方法来说好了很多。
我们都知道,MVDR算法所依赖的参数有两个,一个是噪声协方差矩阵Rnn,还有一个就是导向矢量h。这两个参数的估计准确度越高,自然波束形成的效果也就最好。传统方法对这两个参数的估计主要如以下:
- 对于噪声协方差矩阵来说,可以通过VAD进行语音段和噪声段的判断,然后在噪声段进行噪声协方差矩阵Rnn的计算,但是这种方法相对来说对VAD依赖很严重,一旦VAD性能下降,噪声协方差的估计自然也就下降,这种方法其实鲁棒性并不好。在单通道中,可以利用语音快于噪声功率谱密度的变化,所以可以用SPP算法来进行噪声估计。
- 对于导向矢量来说,可以使用时延估计模块,计算出到达各个麦克风的相对时延,然后代入公式进行计算;还有就是可以通过语音协方差矩阵变换来得到,也就是导向矢量可以近似表示为语音协方差矩阵最大特征值所对应的的特征向量。
对于这篇论文来说,它有以下这样几点新意:
- 论文中的方法利用了空间语音存在概率来获得导向矢量;
- 论文中的噪声协方差矩阵,本质上也是利用语音存在概率来获得的,具体方法在后面来说。
所以说这篇论文所提出的方法的参数只有一个,那就是语音存在概率map的估计。理论上来说,相比之前方法需要估计多个参数来说,这种只需要估计一个参数的方法只需要保证这个参数更加准确就好了。
论文所提方法的过程
下面就来结合图来介绍下整个流程。
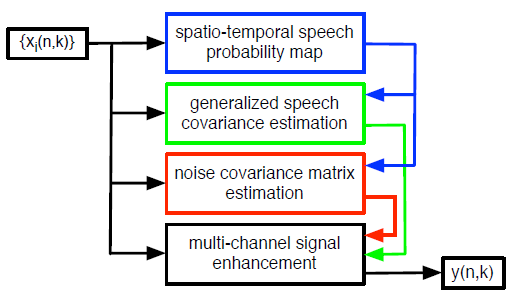
(自己画的图,为了防止不必要的麻烦就不放在这里了,直接借用论文里面的图)
第一步 Spatio-temporal speech probability map:使用GCC-PHAT(广义互相关函数-相位变换法)来进行时延估计,然后利用GCC-PHAT的结果,送入SVM进行训练得到source probability map,计算公式如下:
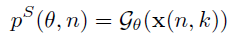
式中,θ表示位置索引、n表示时帧索引,k表示频宽索引,x(n,k)表示多通道语音的SFT。
第二步 Generalized speech and noise covariance estimation:上一步其实我们就得到了这个speech probability map,得到这个map之后,我们就可以带入下面这个公式来计算广义语音协方差矩阵:
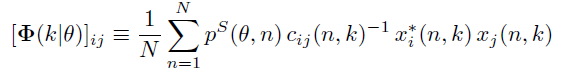
在这里的xi和xj代表的是时域的信号,cij的定义如下
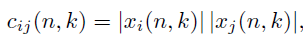
至于我们得到这个广义语音协方差矩阵是做什么用的呢?下一步就知道了。咱们接下来求解噪声协方差矩阵。
我们知道了语音存在概率,那么我们就可以定义一个噪声存在概率。这个噪声存在概率的定义如下面的图中所示。其实这个时候我们要设置一个阈值p0:当ps≥p0的时候,噪声存在概率自然为0;当ps<p0的时候,噪声存在概率为式中所述。记住无论是噪声存在概率还是语音存在概率,其都是第n帧的θ方向的概率。
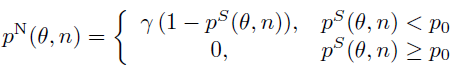
根据噪声存在概率,仿照上面语音协方差矩阵的形式,就可以得到估计的噪声协方差矩阵,如下
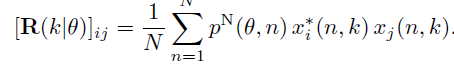
到目前为止,MVDR算法所需要的两个参数中的噪声协方差矩阵这个参数已经求出来了。接下来求导向矢量。
第三步Steering Vector:前面说的语音协方差矩阵就是用到了这里,如下式所示:
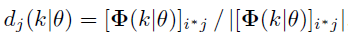
其实就相当于求了一个单位向量而已。
然后把这个也带入MVDR的公示,就可以实现MVDR算法了。更多的内容可以参见论文,也就是参考文献中的论文。
【参考文献】
Anemüller J, Kayser H. Multi-channel signal enhancement with speech and noise covariance estimates computed by a probabilistic localization model[C]//2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017: 156-160.



文章评论